KI Fußball Vorhersage simuliert – Wenn Computer tausende Spiele durchrechnen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Die Idee, ein Fußballspiel nicht vorherzusagen, sondern es virtuell abzuspielen, hat etwas Faszinierendes. Statt eine einzige Wahrscheinlichkeit zu berechnen, lässt man den Computer das Spiel tausende Male durchspielen und schaut, wie oft welches Ergebnis auftritt. Diese Methode der Monte-Carlo-Simulation hat ihren Ursprung in der Atomforschung der 1940er Jahre, ist aber längst in der Welt der Sportanalyse angekommen. Für KI-gestützte Fußballvorhersagen bietet sie einen Ansatz, der sich fundamental von direkten statistischen Modellen unterscheidet und eigene Stärken und Schwächen mitbringt. Simulierte Vorhersagen bei KI Fussball Vorhersage.
Der Name Monte Carlo geht auf das berühmte Spielcasino im Fürstentum Monaco zurück und verweist auf den Kern der Methode: den kontrollierten Einsatz von Zufall. Während deterministische Modelle für eine gegebene Eingabe immer das gleiche Ergebnis liefern, arbeiten Monte-Carlo-Simulationen mit Zufallszahlen und liefern bei jedem Durchlauf ein möglicherweise anderes Ergebnis. Die Magie liegt darin, dass sich aus vielen zufälligen Einzelergebnissen dennoch verlässliche Aussagen über Wahrscheinlichkeiten ableiten lassen. Wenn man ein Spiel zehntausend Mal simuliert und in sechstausend Fällen die Heimmannschaft gewinnt, kann man mit einiger Zuversicht sagen, dass die Heimsiegwahrscheinlichkeit bei etwa 60 Prozent liegt.
Das Prinzip der Monte-Carlo-Simulation
Monte-Carlo-Simulationen basieren auf einem einfachen, aber mächtigen Prinzip: Wenn man einen Prozess mit Zufallskomponenten oft genug wiederholt, konvergieren die beobachteten Häufigkeiten gegen die wahren Wahrscheinlichkeiten. Dieses Gesetz der großen Zahlen ist ein Fundament der Wahrscheinlichkeitstheorie und bildet die theoretische Grundlage für den simulationsbasierten Ansatz.
In der praktischen Anwendung auf Fußball bedeutet das: Man baut ein Modell, das den Verlauf eines Spiels beschreibt, und lässt dieses Modell viele Male mit unterschiedlichen Zufallszahlen laufen. Jeder Durchlauf produziert ein konkretes Ergebnis, etwa 2:1 für die Heimmannschaft. Nach tausenden von Durchläufen kann man auszählen, wie oft jedes mögliche Ergebnis aufgetreten ist, und daraus Wahrscheinlichkeiten ableiten. Die Wahrscheinlichkeit eines 2:1-Heimsiegs ist dann einfach die Anzahl der Durchläufe mit diesem Ergebnis geteilt durch die Gesamtzahl der Durchläufe.
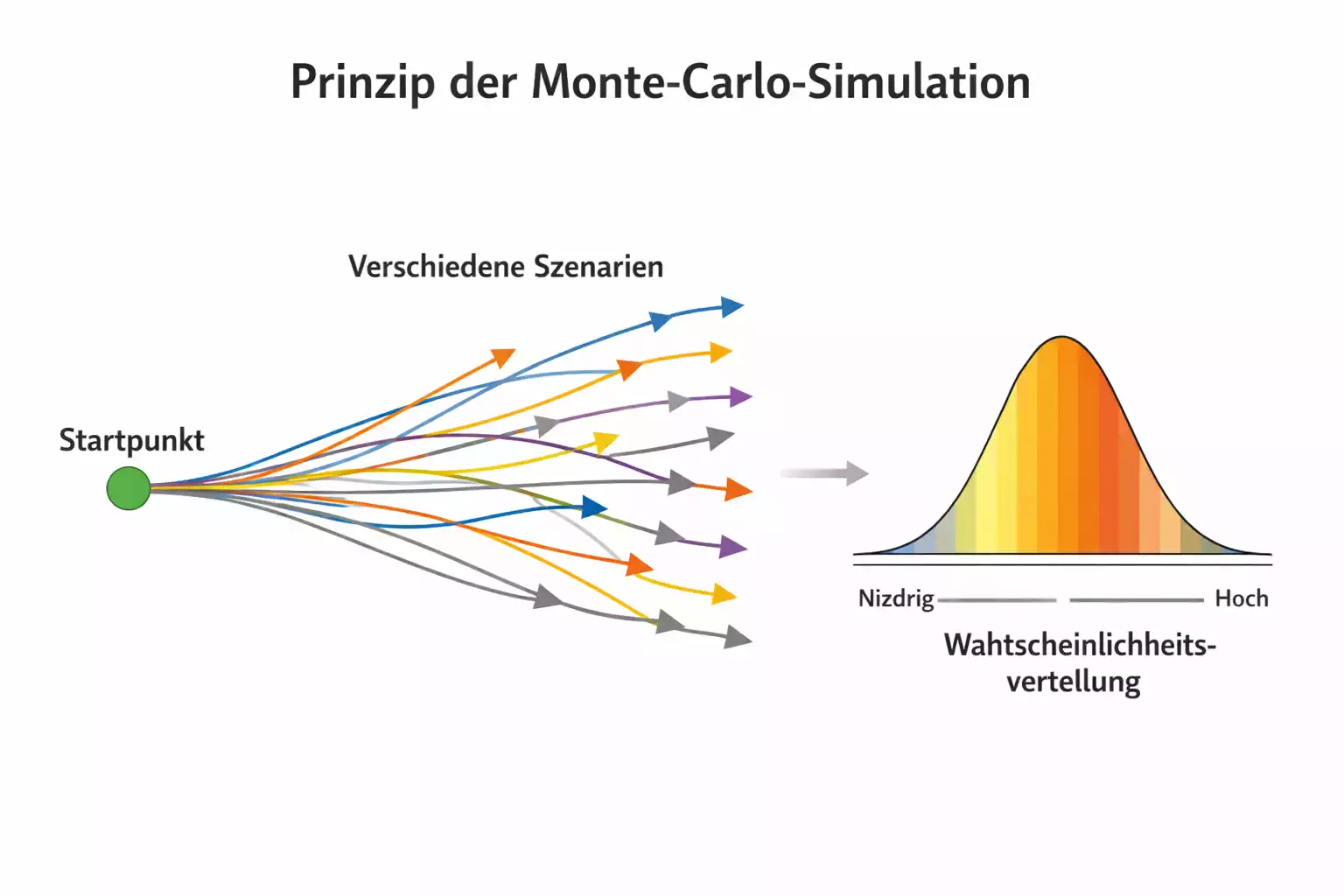
Der Unterschied zu direkten Prognosemodellen liegt in der Art, wie Unsicherheit behandelt wird. Ein direktes Modell wie eine Poisson-Regression berechnet die Wahrscheinlichkeiten analytisch aus den Eingangsparametern. Ein Simulationsmodell generiert die Wahrscheinlichkeiten empirisch durch wiederholtes Durchspielen. Beide Ansätze können zu ähnlichen Ergebnissen führen, haben aber unterschiedliche Vor- und Nachteile. Simulationen sind flexibler und können komplexere Zusammenhänge abbilden, sind aber rechenintensiver und erfordern sorgfältige Modellierung.
Die Qualität einer Monte-Carlo-Simulation hängt entscheidend von der Güte des zugrunde liegenden Modells ab. Ein Simulationsmodell ist nicht automatisch besser als ein analytisches Modell. Es ist genau so gut oder schlecht wie die Annahmen, auf denen es basiert. Wenn das Modell falsche Annahmen macht, werden auch die simulierten Ergebnisse falsch sein, egal wie viele Durchläufe man macht. Die Simulation verstärkt die Fehler des Modells nicht, aber sie korrigiert sie auch nicht.
Aufbau eines Spielsimulationsmodells
Ein Simulationsmodell für Fußballspiele muss den Prozess der Torentstehung abbilden, und hier gibt es viele verschiedene Herangehensweisen mit unterschiedlichem Komplexitätsgrad. Die einfachste Variante modelliert nur die Anzahl der Tore für jede Mannschaft als unabhängige Zufallsvariablen. Komplexere Modelle simulieren den gesamten Spielverlauf mit Ballbesitzphasen, Angriffen, Schüssen und Toren. Die Wahl des richtigen Komplexitätsniveaus ist eine wichtige Entscheidung, die von den verfügbaren Daten, der Rechenleistung und dem Verwendungszweck abhängt.
Die einfachste Herangehensweise nutzt die bereits erwähnte Poisson-Verteilung als Grundlage. Lesen Sie auch xG-basierte Vorhersagen. Für jede Mannschaft wird eine erwartete Torzahl geschätzt, basierend auf ihrer Offensivstärke und der Defensivstärke des Gegners sowie dem Heimvorteil. Dann wird für jede einzelne Simulation ein zufälliger Torwert aus der entsprechenden Poisson-Verteilung gezogen. Die beiden Torwerte bilden dann das Ergebnis dieses simulierten Spiels. Dieser Ansatz ist rechnerisch sehr effizient und liefert für viele Anwendungsfälle gute Ergebnisse, vernachlässigt aber die Dynamik innerhalb des Spiels und kann bestimmte Muster, wie die Häufigkeit von 0:0-Unentschieden, nicht perfekt abbilden.
Fortgeschrittenere Modelle simulieren den zeitlichen Ablauf des Spiels und seine innere Struktur. Sie unterteilen die 90 Minuten in kleine Zeitintervalle, etwa von einer Minute Länge, und bestimmen für jedes Intervall, was passiert: Welche Mannschaft hat Ballbesitz, entwickelt sich daraus ein Angriff, entsteht eine Torchance, fällt ein Tor, oder passiert keines von alledem? Die Wahrscheinlichkeiten für diese verschiedenen Ereignisse hängen von den spezifischen Eigenschaften der beteiligten Mannschaften ab und können auch vom aktuellen Spielstand beeinflusst werden. Ein solches Modell kann beispielsweise erfassen, dass Mannschaften bei Führung typischerweise defensiver spielen und das Tempo herausnehmen, oder dass sie bei Rückstand in der Schlussphase mehr Risiko eingehen und offensiver agieren.
Die sorgfältige Parametrisierung des Modells ist eine kritische und oft unterschätzte Aufgabe. Die zahlreichen Parameter, etwa die durchschnittliche Angriffsrate einer Mannschaft, ihre Schussgenauigkeit, ihre Pressing-Intensität oder ihre Standardsituation-Effizienz, müssen aus historischen Daten geschätzt werden. Diese Schätzungen sind unvermeidlich mit Unsicherheit behaftet, und diese Unsicherheit pflanzt sich durch die gesamte Simulation fort und beeinflusst die Ergebnisse. Ein wirklich gutes Simulationsmodell berücksichtigt diese Parameterunsicherheit explizit, indem es nicht nur einen einzigen festen Parameterwert verwendet, sondern in jeder Simulation aus einer Verteilung von plausiblen Parameterwerten zieht und so die Unsicherheit in den Vorhersagen widerspiegelt.
Die Modellierung von Abhängigkeiten zwischen den beiden Mannschaften ist ein besonders kniffliger Aspekt. In der Realität sind die Torwerte der beiden Teams nicht unabhängig voneinander. Wenn eine Mannschaft sehr offensiv spielt, schießt sie möglicherweise mehr Tore, aber kassiert auch mehr, weil sie hinten Räume öffnet. Wenn beide Mannschaften defensiv eingestellt sind, fallen weniger Tore insgesamt. Diese Korrelationen lassen sich in Simulationsmodellen auf verschiedene Weisen einbauen, etwa durch gemeinsame Faktoren, die beide Torwerte beeinflussen, oder durch explizite Modellierung der taktischen Interaktion zwischen den Teams.
Anwendungsbereiche simulierter Prognosen
Die simulationsbasierte Methode entfaltet ihre besonderen Stärken in Anwendungsfällen, die über einfache Siegwahrscheinlichkeiten hinausgehen. Für komplexe Fragestellungen, die mehrere Faktoren berücksichtigen müssen oder bedingte Wahrscheinlichkeiten erfordern, bietet sie eine Flexibilität, die analytische Modelle oft nicht erreichen können.
Die Vorhersage exakter Endergebnisse ist ein klassischer Anwendungsfall für Simulationen. Während ein analytisches Modell Wahrscheinlichkeiten für verschiedene Torverhältnisse berechnen kann, liefert die Simulation dieselben Wahrscheinlichkeiten auf einem anderen, oft intuitiveren Weg und kann dabei leichter zusätzliche Faktoren und Randbedingungen berücksichtigen. Die Korrelation zwischen den Torzahlen beider Mannschaften, die in rein analytischen Modellen mathematisch schwer zu handhaben ist, ergibt sich in gut konstruierten Simulationen oft natürlich aus der Modellstruktur, ohne dass komplizierte Formeln nötig wären.
Die Berechnung von Saisonprognosen ist ein Bereich, in dem Simulationen ihre Stärken besonders eindrucksvoll ausspielen können. Um die Wahrscheinlichkeit zu berechnen, dass eine bestimmte Mannschaft am Ende der Saison Meister wird, muss man alle verbleibenden Spiele der Saison berücksichtigen und ihre möglichen Ausgänge in allen denkbaren Kombinationen durchspielen. Analytisch ist das bei zehn oder mehr Teams mit jeweils Dutzenden verbleibenden Spielen praktisch unmöglich, die Anzahl der Kombinationen explodiert exponentiell. Mit Simulationen ist es vergleichsweise einfach: Man simuliert die gesamte Restsaison viele tausend Male und zählt am Ende, wie oft jede Mannschaft in der Tabelle oben steht. Das Ergebnis ist eine empirisch ermittelte Meisterwahrscheinlichkeit für jedes Team.

Dieselbe Methode lässt sich auf Abstiegsprognosen, Qualifikation für europäische Wettbewerbe oder beliebige andere Tabellenplatzierungen anwenden. Man kann sogar komplexere Fragen beantworten: Wie wahrscheinlich ist es, dass Team A Meister wird und Team B gleichzeitig absteigt? Solche bedingten Wahrscheinlichkeiten fallen als Nebenprodukt der Simulation quasi automatisch an.
Die Bewertung von Wettmärkten profitiert ebenfalls erheblich von Simulationen. Manche Wettmärkte sind komplex konstruiert und hängen von mehreren Faktoren gleichzeitig ab. Die Wahrscheinlichkeit, dass beide Mannschaften treffen und mehr als 2,5 Tore im Spiel fallen, lässt sich durch Simulation leicht und direkt ermitteln: Man zählt einfach, in wie vielen der simulierten Spiele beide Bedingungen gleichzeitig erfüllt sind. Die analytische Berechnung derselben bedingten Wahrscheinlichkeiten wäre mathematisch aufwendiger und fehleranfälliger.
Live-Simulationen während des laufenden Spiels sind eine fortgeschrittene und besonders spannende Anwendung. Wenn das Spiel bereits läuft und ein bestimmter Spielstand erreicht ist, kann man die verbleibende Spielzeit unter Berücksichtigung der aktuellen Situation simulieren und aktualisierte Wahrscheinlichkeiten berechnen. Wie wahrscheinlich ist es, dass die aktuell führende Mannschaft den Vorsprung über die verbleibende Zeit bringt? Wie wahrscheinlich ist noch ein Ausgleich oder sogar eine Wende? Wie ändern sich diese Wahrscheinlichkeiten mit jeder verstreichenden Minute? Diese dynamischen Fragen lassen sich durch Simulation beantworten, indem man von der aktuellen Spielsituation ausgeht und nur die Restspielzeit simuliert.
Technische Umsetzung und Rechenaufwand
Die praktische Umsetzung von Monte-Carlo-Simulationen erfordert effiziente Algorithmen, sorgfältige Programmierung und ausreichende Rechenleistung. Die gute Nachricht ist, dass moderne Computer selbst aufwendige Simulationen in akzeptabler Zeit durchführen können, und die technischen Hürden sind in den letzten Jahren erheblich gesunken.
Die Anzahl der benötigten Simulationsdurchläufe hängt von der gewünschten Präzision und der Komplexität der Fragestellung ab. Für grobe Schätzungen, etwa ob eine Mannschaft eher als Favorit oder Außenseiter ins Spiel geht, reichen oft schon einige hundert Durchläufe aus. Für präzise Wahrscheinlichkeiten mit kleinen Konfidenzintervallen, wie sie für die Bewertung von Wettquoten nötig sein können, sind Tausende oder Zehntausende von Durchläufen erforderlich. Die statistische Theorie liefert präzise Formeln, um den Zusammenhang zwischen Durchlaufzahl und erreichbarer Präzision zu quantifizieren. Als praktische Faustregel gilt, dass sich die Präzision mit der Quadratwurzel der Durchlaufzahl verbessert: Viermal so viele Durchläufe führen zu doppelter Präzision, also halbierter Unsicherheit.
Die Qualität der verwendeten Zufallszahlen ist ein oft unterschätzter, aber wichtiger Faktor für die Validität der Ergebnisse. Computer können keine echten Zufallszahlen generieren, da sie deterministische Maschinen sind. Stattdessen verwenden sie ausgeklügelte Algorithmen, die sogenannte Pseudozufallszahlen produzieren. Diese Zahlen sehen zufällig aus und verhalten sich statistisch wie echte Zufallszahlen, sind aber tatsächlich durch eine mathematische Formel aus einem Startwert berechnet. Für die allermeisten Anwendungen in der Spielsimulation sind moderne Pseudozufallsgeneratoren völlig ausreichend und praktisch nicht von echtem Zufall zu unterscheiden. Schlechte oder veraltete Generatoren können jedoch zu systematischen Verzerrungen führen, etwa wenn sie bestimmte Zahlenfolgen bevorzugen oder unerwünschte Muster aufweisen. Professionelle Simulationssoftware verwendet daher bewährte und intensiv getestete Algorithmen wie den Mersenne Twister, die für statistische Anwendungen validiert sind und als sicher gelten.

Die Parallelisierung ist ein mächtiges Werkzeug, um auch sehr umfangreiche Simulationen in praktikablen Zeitrahmen durchzuführen. Da die einzelnen Durchläufe einer Monte-Carlo-Simulation unabhängig voneinander sind und nicht aufeinander aufbauen, können sie ohne Weiteres auf mehreren Prozessoren oder sogar auf vielen Computern gleichzeitig ausgeführt werden. Ein Simulationslauf, der auf einem einzelnen Prozessor eine Stunde dauern würde, kann auf hundert Prozessoren theoretisch in weniger als einer Minute abgeschlossen werden. In der Praxis gibt es einen gewissen Overhead für die Koordination und Zusammenführung der Ergebnisse, aber die Beschleunigung ist dennoch enorm. Cloud-Computing-Dienste wie AWS, Google Cloud oder Azure machen solche massive Rechenleistung heute auch für kleine Anbieter und sogar für Privatpersonen erschwinglich, da man nur für die tatsächlich genutzte Rechenzeit bezahlt.
Die Speicherung und Auswertung der Simulationsergebnisse erfordert ebenfalls Aufmerksamkeit. Bei Millionen von Durchläufen entstehen große Datenmengen, die effizient gespeichert und verarbeitet werden müssen. Moderne Datenbanken und Big-Data-Tools können diese Herausforderung bewältigen, aber die Architektur muss von Anfang an darauf ausgelegt sein. Oft ist es sinnvoll, nicht alle Einzelergebnisse zu speichern, sondern nur aggregierte Statistiken zu berechnen, die für die gewünschten Auswertungen benötigt werden.
Validierung und Qualitätskontrolle
Wie bei allen Vorhersagemodellen ist die sorgfältige Validierung entscheidend für die Beurteilung der Qualität und Zuverlässigkeit. Bei Simulationsmodellen kommen spezifische Herausforderungen hinzu, die über die übliche Modellvalidierung hinausgehen und besondere Aufmerksamkeit erfordern.
Die Konvergenzprüfung stellt sicher, dass genügend Durchläufe durchgeführt wurden, um stabile und verlässliche Ergebnisse zu erhalten. Man kann die Ergebnisse nach unterschiedlich vielen Durchläufen systematisch vergleichen und prüfen, ob sie sich stabilisiert haben. Wenn die geschätzte Siegwahrscheinlichkeit nach tausend Durchläufen 58 Prozent beträgt und nach zehntausend Durchläufen 59 Prozent, ist das Ergebnis wahrscheinlich zuverlässig und hat sich eingependelt. Wenn es nach tausend Durchläufen 55 Prozent und nach zehntausend Durchläufen 65 Prozent beträgt, waren tausend Durchläufe offensichtlich nicht genug für eine zuverlässige Schätzung. Professionelle Simulationssoftware bietet oft automatische Konvergenzprüfungen an, die signalisieren, wenn die Ergebnisse hinreichend stabil sind.
Die Kalibrierung des Simulationsmodells muss wie bei jedem Vorhersagemodell anhand historischer Daten überprüft werden. Wenn das Modell vielen Spielen eine 70-prozentige Heimsiegwahrscheinlichkeit zuweist, sollten tatsächlich etwa 70 Prozent dieser Spiele mit einem Heimsieg enden. Systematische Abweichungen zwischen vorhergesagten und beobachteten Häufigkeiten deuten auf Fehler im Modell hin, etwa eine falsche Schätzung des Heimvorteils, eine unrealistische Torverteilung oder fehlende Berücksichtigung wichtiger Faktoren. Die Kalibrierung sollte für verschiedene Teilmengen der Daten geprüft werden: Stimmen die Vorhersagen für Top-Teams? Für Abstiegskandidaten? Für Derbys? Eine gute Kalibrierung insgesamt kann lokale Fehlkalibrierungen verbergen.
Der systematische Vergleich mit analytischen Modellen kann als wertvolle Plausibilitätsprüfung dienen. Für einfache Fälle, in denen analytische Lösungen bekannt sind und berechnet werden können, sollten die Simulationsergebnisse mit diesen übereinstimmen. Wenn ein Poisson-Modell eine bestimmte Ergebnisverteilung vorhersagt und die Simulation auf Basis der gleichen Annahmen deutlich andere Ergebnisse liefert, ist entweder die Simulation falsch implementiert oder es werden zusätzliche Faktoren berücksichtigt, die erklären sollten, woher die Unterschiede kommen. Diese Art der Kreuzvalidierung hilft, Implementierungsfehler aufzudecken, bevor sie zu falschen Vorhersagen führen.
Die Out-of-Sample-Validierung ist besonders wichtig, um Überanpassung zu vermeiden. Ein Modell, das auf historischen Daten trainiert wurde, sollte auf Daten getestet werden, die nicht für das Training verwendet wurden. Wenn das Modell auf den Trainingsdaten gut funktioniert, aber auf neuen Daten versagt, ist es überangepasst und hat spezifische Eigenheiten der Trainingsdaten gelernt statt allgemeiner Muster. Die strikte Trennung von Trainings- und Testdaten ist eine Grundregel der Modellvalidierung, die auch für Simulationsmodelle gilt.
Kombination mit anderen Methoden
Simulationsmodelle stehen nicht in Konkurrenz zu anderen Methoden, sondern können sinnvoll mit ihnen kombiniert werden. Die Integration verschiedener Ansätze führt oft zu robusteren Vorhersagen als jeder Ansatz allein.
Die Parameterschätzung für Simulationsmodelle nutzt oft statistische Methoden. Die Angriffsrate einer Mannschaft oder ihre Schusseffizienz werden aus historischen Daten geschätzt, typischerweise mit Regressionsmodellen oder bayesianischen Methoden. Die Simulation übernimmt dann diese Parameter und generiert daraus Vorhersagen für zukünftige Spiele. Die Qualität der Parameterschätzung bestimmt die Qualität der Simulation.
Machine Learning kann die Parameterschätzung verbessern. Neuronale Netze oder Gradient-Boosting-Modelle können komplexe Zusammenhänge in den Daten erfassen, die einfache statistische Modelle übersehen. Diese ML-Modelle liefern dann die Eingabeparameter für die Simulation. Die Kombination von datengetriebener Parameterschätzung und simulationsbasierter Prognose verbindet die Stärken beider Welten.
Ensemble-Methoden kombinieren die Vorhersagen mehrerer Modelle, darunter möglicherweise sowohl Simulationsmodelle als auch analytische Modelle. Wenn verschiedene Modelle zu ähnlichen Ergebnissen kommen, erhöht das die Zuversicht in die Vorhersage. Wenn sie zu unterschiedlichen Ergebnissen kommen, ist Vorsicht geboten, und die Gründe für die Unterschiede sollten untersucht werden.
Grenzen der Simulation
Wie jede Methode hat auch die Monte-Carlo-Simulation ihre Grenzen, die man kennen sollte, um ihre Ergebnisse richtig einzuordnen und keine unrealistischen Erwartungen zu entwickeln. Die Simulation ist ein mächtiges Werkzeug, aber sie ist nicht allmächtig.
Die fundamentalste Grenze ist die unvermeidliche Modellabhängigkeit. Eine Simulation ist nur genau so gut wie das Modell, das simuliert wird. Wenn das Modell wichtige Faktoren ignoriert, falsche Annahmen macht oder auf unzureichenden Daten basiert, werden auch die Simulationsergebnisse entsprechend falsch oder irreführend sein. Die Simulation selbst fügt keine neue Information hinzu und kann keine Mängel des zugrunde liegenden Modells kompensieren. Sie extrahiert lediglich die Implikationen des Modells auf eine Weise, die analytisch nicht zugänglich wäre. Das Garbage-in-Garbage-out-Prinzip gilt hier uneingeschränkt: Schlechte Modellannahmen führen zu schlechten Vorhersagen, egal wie viele Simulationsdurchläufe man durchführt.
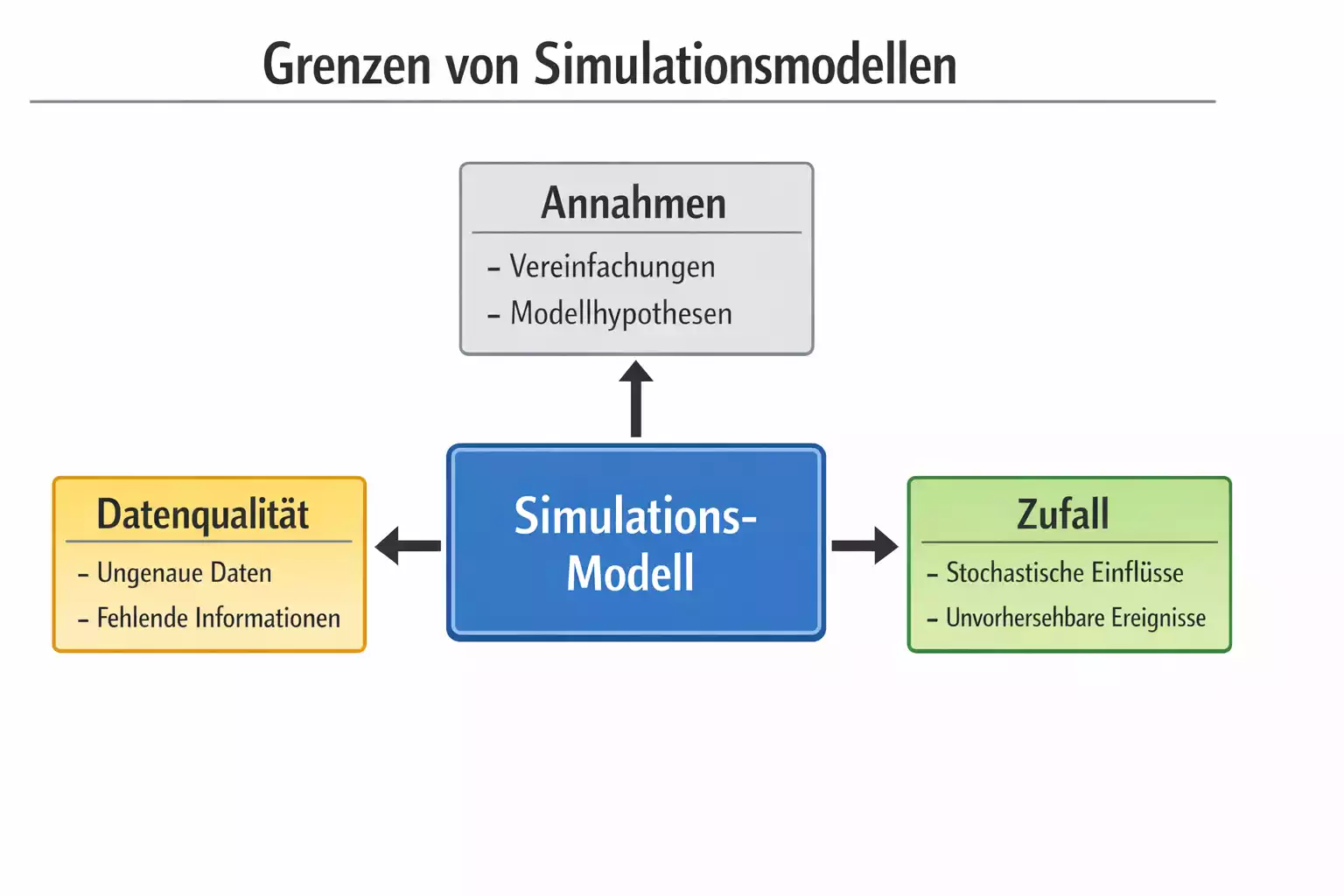
Der Rechenaufwand kann bei sehr komplexen Modellen oder sehr großen Simulationsumfängen trotz moderner Hardware prohibitiv werden. Obwohl Computer heute leistungsfähiger sind als je zuvor, gibt es praktische Grenzen dessen, was in akzeptabler Zeit berechnet werden kann. Ein Modell, das einzelne Spielzüge und Spieleraktionen simuliert, ist rechentechnisch weitaus aufwendiger als eines, das nur aggregierte Torverhältnisse simuliert. Die Entscheidung für ein bestimmtes Detailniveau ist daher immer ein Kompromiss zwischen theoretisch erreichbarer Genauigkeit und praktischer Durchführbarkeit. Nicht alles, was konzeptionell möglich wäre, ist auch praktikabel.
Die Interpretierbarkeit kann leiden, wenn Simulationsmodelle zu komplex werden und viele verschiedene Komponenten und Interaktionen enthalten. Ein einfaches Poisson-Modell ist leicht zu verstehen: Die erwartete Torzahl bestimmt direkt die Wahrscheinlichkeitsverteilung, und man kann nachvollziehen, wie eine Änderung der Parameter sich auswirkt. Ein komplexes Simulationsmodell mit Dutzenden von Parametern, nichtlinearen Interaktionen und emergenten Verhaltensweisen kann schwerer zu durchschauen sein. Wenn die Simulation ein überraschendes oder kontraintuitives Ergebnis liefert, ist es nicht immer einfach zu verstehen, warum genau das so ist und welche Faktoren dafür verantwortlich sind. Diese Black-Box-Eigenschaft kann problematisch sein, wenn man die Ergebnisse erklären oder verteidigen muss.
Die Sensitivität gegenüber Parameteränderungen ist ein weiterer Aspekt, der Aufmerksamkeit verdient. Kleine Änderungen in den Eingangsparametern können manchmal zu überproportional großen Änderungen in den Ergebnissen führen, besonders bei nichtlinearen Modellen. Diese Sensitivität ist nicht unbedingt ein Fehler, sie kann die tatsächliche Unsicherheit widerspiegeln, aber sie erfordert eine sorgfältige Analyse, um robuste Schlussfolgerungen zu ziehen.
Die Monte-Carlo-Simulation ist ein mächtiges und vielseitiges Werkzeug im Arsenal der KI-Fußballvorhersage. Sie bietet Flexibilität für komplexe Fragestellungen und kann Zusammenhänge abbilden, die analytisch schwer zu fassen sind. Saisonprognosen, bedingte Wahrscheinlichkeiten, komplexe Wettmärkte und Live-Updates sind Anwendungsfälle, in denen Simulationen ihre Stärken voll ausspielen können. Aber sie ist kein Allheilmittel und ersetzt nicht die sorgfältige Modellierung und gründliche Validierung. Am Ende zählt nicht die verwendete Methode, sondern die tatsächliche Qualität der Vorhersagen, und diese hängt von vielen Faktoren ab, von denen die Wahl zwischen Simulation und analytischer Lösung nur einer unter vielen ist.
Die Zukunft der Spielsimulation liegt wahrscheinlich in der Kombination verschiedener Methoden. Machine Learning für die Parameterschätzung, klassische Statistik für die Modellstruktur, und Monte-Carlo-Simulation für die Auswertung komplexer Szenarien ergänzen einander auf natürliche Weise. Die steigende Verfügbarkeit von Cloud-Computing macht immer aufwendigere Simulationen praktikabel, während bessere Daten immer realistischere Modelle ermöglichen. Die Grenzen dessen, was simuliert werden kann, verschieben sich stetig.
Für den Nutzer von KI-Fußballvorhersagen ist das Verständnis der Simulationsmethodik wertvoll, auch wenn man selbst keine Simulationen durchführt. Es hilft zu verstehen, wie Saisonprognosen zustande kommen, warum bestimmte Wahrscheinlichkeiten als Spannen statt als Punktschätzungen angegeben werden, und welche Unsicherheiten in den Vorhersagen stecken. Die Monte-Carlo-Simulation mag ihren Namen einem Spielcasino verdanken, aber ihre Anwendung in der Fußballanalyse ist alles andere als Glücksspiel. Sie ist ein systematischer, mathematisch fundierter Ansatz, um mit der inhärenten Unsicherheit des Sports umzugehen und aus dieser Unsicherheit dennoch nützliche Erkenntnisse zu gewinnen.