KI Fußball Vorhersage statistisch – Die Mathematik hinter den Prognosen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Statistik und Fußball wirken auf den ersten Blick wie ein ungleiches Paar. Der eine Begriff beschwört Bilder von Tabellen, Formeln und abstrakten Zahlenreihen herauf, der andere steht für Emotionen, Überraschungen und das Unberechenbare. Doch gerade diese Spannung macht die statistische Analyse des Fußballs so faszinierend. Hinter jeder KI-gestützten Vorhersage verbirgt sich ein mathematisches Fundament, das aus Rohdaten Wahrscheinlichkeiten destilliert. Wer verstehen möchte, wie diese Systeme funktionieren und wo ihre Grenzen liegen, muss sich mit den statistischen Grundlagen auseinandersetzen, die ihnen zugrunde liegen.
Die Entwicklung statistischer Methoden im Fußball ist keine Erfindung des digitalen Zeitalters, auch wenn es manchmal so erscheinen mag. Bereits in den 1950er Jahren begannen vereinzelte Trainer und Analysten, systematisch Daten zu sammeln und auszuwerten, um Muster zu erkennen und Entscheidungen zu verbessern. Was sich seither fundamental verändert hat, ist das Ausmaß und die Raffinesse dieser Analyse sowie die Geschwindigkeit, mit der sie durchgeführt werden kann. Moderne KI-Systeme verarbeiten Millionen von Datenpunkten in Sekundenbruchteilen und wenden komplexe mathematische Modelle an, die vor wenigen Jahrzehnten schlicht nicht in akzeptabler Zeit berechenbar gewesen wären. Die Grundprinzipien jedoch, die Logik der Wahrscheinlichkeit und der statistischen Inferenz, sind dieselben geblieben und wurden nicht neu erfunden.
Von der Deskription zur Prognose
Der Weg von der bloßen Beschreibung vergangener Ereignisse zur Vorhersage zukünftiger Ergebnisse ist der zentrale Sprung, den statistische Modelle vollziehen müssen. Deskriptive Statistik fasst zusammen, was passiert ist: wie viele Tore eine Mannschaft geschossen hat, wie hoch der Ballbesitz war, wie viele Zweikämpfe gewonnen wurden. Diese Informationen sind nützlich, aber sie sagen noch nichts darüber aus, was in Zukunft passieren wird. Der Übergang zur Inferenzstatistik und schließlich zur Prognose erfordert zusätzliche Annahmen und Methoden.
Die grundlegende Idee hinter statistischen Prognosen ist die Extrapolation von Mustern. Wenn eine Mannschaft in der Vergangenheit unter bestimmten Bedingungen bestimmte Ergebnisse erzielt hat, und wenn diese Bedingungen sich nicht grundlegend geändert haben, dann ist es wahrscheinlich, dass ähnliche Ergebnisse auch in Zukunft auftreten werden. Diese Annahme der Kontinuität ist fundamental für jede statistische Vorhersage und gleichzeitig ihre größte Schwachstelle. Fußball ist ein dynamischer Sport, in dem sich Bedingungen ständig ändern: Spieler werden verletzt, Trainer wechseln, Taktiken entwickeln sich weiter. Ein gutes statistisches Modell muss diese Dynamik berücksichtigen und dennoch aus den verfügbaren Daten sinnvolle Schlüsse ziehen.

Die Varianz ist ein Konzept, das für das Verständnis statistischer Fußballprognosen unverzichtbar ist. Sie misst, wie stark einzelne Beobachtungen vom Durchschnitt abweichen. Im Fußball ist die Varianz besonders hoch, weil Tore seltene Ereignisse sind und einzelne Spiele durch Zufälle entschieden werden können. Eine Mannschaft, die im Durchschnitt 1,5 Tore pro Spiel erzielt, wird nicht in jedem Spiel genau 1,5 Tore schießen. Manchmal sind es null, manchmal drei, manchmal fünf. Diese Schwankungen erschweren Vorhersagen und erfordern Modelle, die mit Unsicherheit umgehen können.
Die Regression zur Mitte ist ein weiteres fundamentales Konzept, das oft missverstanden wird. Es besagt, dass extreme Beobachtungen dazu tendieren, von weniger extremen Beobachtungen gefolgt zu werden. Eine Mannschaft, die fünf Spiele in Folge gewonnen hat, wird nicht notwendigerweise ewig weitersiegen. Ihre Leistung wird wahrscheinlich irgendwann wieder näher an ihren langfristigen Durchschnitt rücken. Dieses Phänomen ist keine mysteriöse Kraft, sondern eine mathematische Konsequenz der Varianz. Statistische Modelle nutzen es, um übertriebene Erwartungen zu korrigieren und realistischere Prognosen zu erstellen.
Die Datenbasis statistischer Modelle
Jedes statistische Modell ist nur so gut wie die Daten, auf denen es basiert. Diese scheinbar banale Feststellung hat weitreichende Konsequenzen für die Praxis der Fußballvorhersage. Die Qualität, Vollständigkeit und Relevanz der Eingangsdaten bestimmt maßgeblich die Qualität der Ausgabe. Für Fußballvorhersagen existiert eine Vielzahl von Datenquellen, die von einfachen Ergebnislisten bis zu hochdetaillierten Tracking-Daten reichen. Das Verständnis dieser Datenbasis und ihrer jeweiligen Stärken und Schwächen hilft dabei, die Möglichkeiten und Grenzen statistischer Prognosen realistisch einzuschätzen.
Die grundlegendsten Daten sind die Spielergebnisse selbst: wer gegen wen gespielt hat, an welchem Datum, ob zu Hause oder auswärts, und wie das Spiel ausgegangen ist. Diese Daten sind für die meisten Ligen über Jahrzehnte hinweg verfügbar und bilden die Basis für einfache, aber durchaus effektive Modelle wie Elo-Ratings. Sie haben den großen Vorteil, dass sie vollständig objektiv und leicht zugänglich sind. Ihr offensichtlicher Nachteil ist, dass sie keine Information über den tatsächlichen Spielverlauf enthalten. Ein 1:0-Sieg nach einem späten Glückstreffer in der Nachspielzeit und ein 1:0-Sieg nach neunzig Minuten totaler Dominanz erscheinen in den reinen Ergebnisdaten vollkommen identisch, obwohl sie fundamental unterschiedliche Aussagen über die Spielstärke der beteiligten Mannschaften machen.
Die nächste Ebene umfasst aggregierte Spielstatistiken: Torschüsse, Schüsse aufs Tor, Ballbesitz, Ecken, Fouls, Abseits und ähnliche Kennzahlen, die während des Spiels erfasst werden. Diese Daten geben ein deutlich genaueres Bild des Spielverlaufs und erlauben differenziertere Analysen als reine Ergebnisse. Eine Mannschaft, die 20 Torschüsse hatte und nur einen einzigen Treffer erzielte, ist wahrscheinlich anders zu bewerten als eine, die aus lediglich drei Schüssen ein Tor machte. Die erste hatte möglicherweise Pech, die zweite möglicherweise Glück. Aggregierte Statistiken sind für die großen europäischen Ligen gut verfügbar und werden von den meisten modernen Vorhersagemodellen als wichtige Eingangsvariablen genutzt.
Die detaillierteste und aufschlussreichste Ebene umfasst Event-Daten und Tracking-Daten, die erst in den letzten Jahren breiter verfügbar geworden sind. Event-Daten dokumentieren jeden einzelnen Ballkontakt im Spiel: wer den Ball hatte, was er damit gemacht hat, wohin der Ball ging, und was als nächstes passierte. Tracking-Daten gehen noch einen Schritt weiter und erfassen die Position jedes einzelnen Spielers auf dem Platz in Echtzeit, typischerweise mit einer Frequenz von 25 Bildern pro Sekunde. Diese Daten ermöglichen fortgeschrittene Analysen wie Expected Goals, taktische Auswertungen und detaillierte Spielerbewertungen. Ihr Nachteil ist die eingeschränkte Verfügbarkeit: Sie existieren hauptsächlich für die Topligen und sind oft nur gegen erhebliche Gebühren von spezialisierten Anbietern wie Opta, StatsBomb oder Wyscout zugänglich.
Die sorgfältige Aufbereitung der Rohdaten für statistische Modelle ist eine eigene Kunst, die in Fachkreisen als Feature Engineering bezeichnet wird. Die Rohdaten in ihrer ursprünglichen Form sind oft nicht direkt für Modelle nutzbar und müssen in Variablen transformiert werden, die für das Modell tatsächlich nützlich und aussagekräftig sind. Statt einfach nur die rohe Anzahl der Torschüsse zu verwenden, könnte man beispielsweise die Torschüsse pro Ballbesitzminute berechnen, um die Effizienz der Offensivaktionen zu messen. Man könnte die durchschnittliche Distanz der Schüsse zum Tor erfassen oder den Anteil der Schüsse aus dem Strafraum. Die Wahl der richtigen Features kann die Vorhersagekraft eines Modells erheblich verbessern und ist oft der entscheidende Unterschied zwischen einem mittelmäßigen und einem wirklich guten System.
Die Poisson-Verteilung und ihre Anwendung
Ein statistisches Werkzeug, das für Fußballvorhersagen besonders relevant ist, ist die Poisson-Verteilung. Sie beschreibt die Wahrscheinlichkeit, dass eine bestimmte Anzahl von Ereignissen in einem festen Zeitraum eintritt, wenn diese Ereignisse unabhängig voneinander und mit konstanter Rate auftreten. Diese Annahmen passen nicht perfekt auf Fußball, aber gut genug, um nützliche Vorhersagen zu ermöglichen.
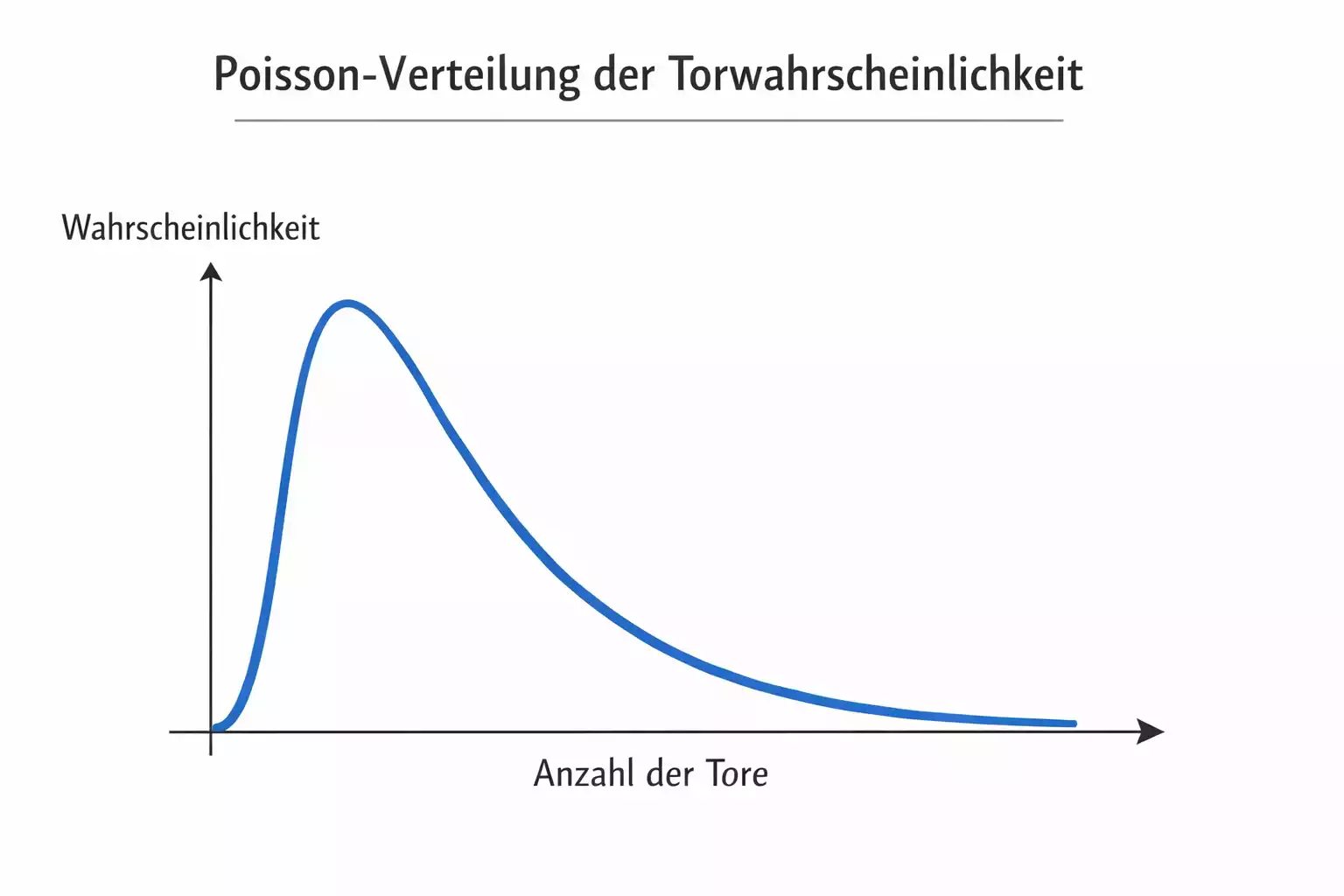
Die Anwendung auf Fußball funktioniert folgendermaßen: Man schätzt die durchschnittliche Anzahl von Toren, die eine Mannschaft pro Spiel erzielt, und die durchschnittliche Anzahl, die sie kassiert. Aus diesen Werten und der entsprechenden Stärke des Gegners berechnet man die erwartete Torzahl für ein bestimmtes Spiel. Die Poisson-Verteilung liefert dann die Wahrscheinlichkeiten für verschiedene Torverhältnisse. Die Wahrscheinlichkeit eines 2:1-Sieges lässt sich berechnen, indem man die Wahrscheinlichkeit für genau zwei Heimtore mit der Wahrscheinlichkeit für genau ein Auswärtstor multipliziert.
Die Stärke der Poisson-Modelle liegt in ihrer Einfachheit und Transparenz. Man kann genau nachvollziehen, wie die Vorhersagen zustande kommen, und die Parameter haben eine klare inhaltliche Bedeutung. Die Schwäche liegt in den vereinfachenden Annahmen. Tore im Fußball sind nicht wirklich unabhängig voneinander: Ein Tor verändert die Spielsituation und beeinflusst die Wahrscheinlichkeit weiterer Tore. Mannschaften passen ihr Verhalten an den Spielstand an. Diese Effekte werden von einfachen Poisson-Modellen nicht erfasst.
Fortgeschrittene Varianten des Poisson-Ansatzes versuchen, diese Einschränkungen zu überwinden. Bivariate Poisson-Modelle berücksichtigen die Korrelation zwischen den Torwerten beider Mannschaften. Dynamische Modelle passen die Parameter im Laufe der Zeit an und berücksichtigen, dass sich die Stärke von Mannschaften verändert. Zero-inflated Poisson-Modelle korrigieren für die Tatsache, dass 0:0-Unentschieden häufiger vorkommen, als das einfache Modell vorhersagt. Diese Erweiterungen verbessern die Vorhersagegenauigkeit, erhöhen aber auch die Komplexität.
Elo-Ratings und verwandte Systeme
Ein anderer fundamentaler Ansatz zur statistischen Fußballvorhersage basiert auf Rating-Systemen, von denen das Elo-System das bekannteste und am weitesten verbreitete ist. Ursprünglich für Schach entwickelt vom ungarisch-amerikanischen Physiker Arpad Elo, wurde es in den letzten Jahrzehnten erfolgreich auf Fußball und zahlreiche andere Sportarten übertragen. Die Grundidee ist elegant in ihrer Einfachheit: Jede Mannschaft hat einen Rating-Wert, der ihre relative Stärke im Vergleich zu allen anderen Mannschaften ausdrückt. Nach jedem Spiel werden die Ratings beider beteiligten Mannschaften basierend auf dem Ergebnis und der vorherigen Erwartung angepasst.
Das Elo-System berücksichtigt bei der Anpassung die erwartete Gewinnwahrscheinlichkeit, die sich aus der Rating-Differenz ergibt. Wenn eine hochbewertete Mannschaft gegen eine niedrigbewertete gewinnt, entspricht das der Erwartung, und die Ratings ändern sich nur geringfügig. Wenn hingegen die niedrigbewertete Mannschaft gewinnt, ist das eine Überraschung, die mehr Information enthält, und beide Ratings ändern sich entsprechend stärker. Diese selbstkorrigierende Mechanik sorgt dafür, dass die Ratings im Laufe der Zeit die tatsächliche Spielstärke immer besser und präziser widerspiegeln, solange genügend Spiele gespielt werden.
Für die Anwendung auf Fußball wurden verschiedene wichtige Anpassungen am klassischen Elo-System vorgenommen, die den Besonderheiten des Sports Rechnung tragen. Die Tordifferenz wird in den meisten Fußball-Elo-Varianten berücksichtigt, nicht nur das bloße Ergebnis. Ein überzeugender 3:0-Sieg sagt mehr über die Spielstärke aus als ein knappes 1:0 und sollte logischerweise zu einer stärkeren Rating-Anpassung führen. Der Heimvorteil wird typischerweise eingerechnet, indem die Heimmannschaft einen Rating-Bonus erhält, der bei der Berechnung der erwarteten Gewinnwahrscheinlichkeit berücksichtigt wird. Die Gewichtung neuerer Spiele gegenüber älteren kann durch einen sogenannten K-Faktor gesteuert werden, um schneller auf Formveränderungen zu reagieren oder stabiler gegenüber kurzfristigen Schwankungen zu sein.
Die unbestreitbare Stärke von Elo-basierten Systemen liegt in ihrer Robustheit und unmittelbaren Interpretierbarkeit. Die Ratings haben eine klare inhaltliche Bedeutung, sie lassen sich direkt vergleichen, und ihre Entwicklung über die Zeit hinweg lässt sich nachvollziehen und analysieren. Eine Mannschaft mit einem Rating von 1800 ist stärker als eine mit 1600, und die Differenz erlaubt eine direkte Berechnung der Gewinnwahrscheinlichkeit. Die offensichtliche Schwäche liegt darin, dass sie ausschließlich Ergebnisse berücksichtigen, nicht den tatsächlichen Spielverlauf. Eine Mannschaft, die durch einen glücklichen Abpraller in der Nachspielzeit gewonnen hat, erhält exakt die gleiche Rating-Verbesserung wie eine, die das Spiel von Anfang bis Ende dominiert und verdient gewonnen hat. Diese Blindheit gegenüber der Spielqualität kann zu systematischen Verzerrungen führen, besonders bei kleinen Stichproben.
Bayesianische Methoden in der Sportanalyse
Die bayesianische Statistik bietet einen alternativen Rahmen für Vorhersagen, der in den letzten Jahren zunehmend populär geworden ist. Im Gegensatz zum klassischen frequentistischen Ansatz behandelt die bayesianische Statistik Wahrscheinlichkeiten als Ausdruck von Unsicherheit und erlaubt die explizite Einbeziehung von Vorwissen in die Analyse.
Die Grundidee ist das Bayes-Theorem, das beschreibt, wie man Überzeugungen angesichts neuer Evidenz aktualisieren sollte. Man beginnt mit einer Priori-Verteilung, die das Vorwissen über die zu schätzenden Parameter ausdrückt. Dann beobachtet man Daten und berechnet die Posteriori-Verteilung, die das aktualisierte Wissen widerspiegelt. Diese Posteriori-Verteilung kann dann für Vorhersagen genutzt werden.
Für Fußballvorhersagen bietet der bayesianische Ansatz mehrere Vorteile. Er kann mit kleinen Datenmengen umgehen, indem er Vorwissen einbezieht. Am Anfang einer Saison, wenn nur wenige Spiele gespielt wurden, kann das Vorwissen aus der vergangenen Saison die Prognosen stabilisieren. Er liefert vollständige Wahrscheinlichkeitsverteilungen, nicht nur Punktschätzungen. Statt zu sagen, dass Bayern München zu 70 Prozent gewinnt, kann ein bayesianisches Modell die Unsicherheit dieser Schätzung quantifizieren.
Die praktische Umsetzung bayesianischer Modelle ist rechnerisch aufwendiger als klassische Methoden. Oft werden Simulationsverfahren wie Markov Chain Monte Carlo verwendet, um die Posteriori-Verteilungen zu approximieren. Diese Verfahren erfordern erhebliche Rechenleistung, die aber mit moderner Hardware verfügbar ist. Der zusätzliche Aufwand lohnt sich besonders in Situationen mit wenig Daten oder wenn die Quantifizierung von Unsicherheit wichtig ist.
Interpretation statistischer Vorhersagen
Die Ausgabe eines statistischen Modells ist typischerweise eine Wahrscheinlichkeit: 60 Prozent Chance auf einen Heimsieg, 25 Prozent auf ein Unentschieden, 15 Prozent auf einen Auswärtssieg. Diese Zahlen scheinen präzise und wissenschaftlich fundiert, aber ihre korrekte Interpretation erfordert ein tiefes Verständnis für das, was sie tatsächlich aussagen und was nicht. Viele Missverständnisse und Enttäuschungen im Umgang mit statistischen Vorhersagen resultieren aus einer falschen Interpretation dieser Wahrscheinlichkeiten.
Eine Wahrscheinlichkeit von 60 Prozent bedeutet ausdrücklich nicht, dass das Ereignis mit Sicherheit eintritt. Es bedeutet, dass bei sehr vielen ähnlichen Situationen das Ereignis in etwa 60 Prozent der Fälle eintreten würde. Im konkreten Einzelfall, dem einen Spiel, das tatsächlich stattfindet, wird entweder der eine oder der andere Ausgang eintreten. Es gibt kein halbes Ergebnis, keine partielle Realität. Die Vorhersage kann methodisch korrekt sein und das vorhergesagte Ereignis tritt dennoch nicht ein, weil die 40-Prozent-Alternative Realität wurde. Oder die Vorhersage kann methodisch fragwürdig sein und das Ereignis tritt trotzdem ein, weil man zufällig richtig lag. Die Qualität einer einzelnen Vorhersage lässt sich am Einzelergebnis nicht beurteilen. Erst über viele Fälle hinweg, über Dutzende oder Hunderte von Spielen, zeigt sich, ob ein Modell tatsächlich gut kalibriert ist.
Konfidenzintervalle sind ein wichtiges Werkzeug, um die Unsicherheit von Schätzungen transparent auszudrücken und zu kommunizieren. Ein 95-Prozent-Konfidenzintervall für die Siegwahrscheinlichkeit könnte beispielsweise von 55 bis 65 Prozent reichen. Das bedeutet, dass die wahre, aber unbekannte Wahrscheinlichkeit mit hoher statistischer Sicherheit in diesem Bereich liegt. Je breiter das Intervall, desto unsicherer ist die zugrunde liegende Schätzung und desto vorsichtiger sollte man mit Schlussfolgerungen sein. Enge Konfidenzintervalle sind nur möglich, wenn viele relevante und hochwertige Daten vorliegen und das Modell nachweislich gut kalibriert ist. Leider werden Konfidenzintervalle in der Kommunikation von Vorhersagen oft weggelassen, was zu einer falschen Präzision führt.
Die Kalibrierung eines Modells beschreibt, wie gut die vorhergesagten Wahrscheinlichkeiten mit den tatsächlich beobachteten Häufigkeiten übereinstimmen. Ein gut kalibriertes Modell, das vielen Spielen eine 70-prozentige Heimsiegwahrscheinlichkeit zuweist, sollte in etwa 70 Prozent dieser Spiele tatsächlich einen Heimsieg beobachten. Wenn es in der Realität nur 60 Prozent sind, ist das Modell überkonfident und seine Vorhersagen systematisch zu aggressiv zugunsten der Heimmannschaft. Wenn es 80 Prozent sind, ist das Modell unterkonfident und unterschätzt die Heimstärke systematisch. Die sorgfältige Überprüfung der Kalibrierung anhand historischer Daten ist ein unverzichtbarer Schritt bei der Evaluation und Auswahl statistischer Modelle und sollte vor jedem praktischen Einsatz durchgeführt werden.
Statistische Herausforderungen im Fußball
Fußball stellt statistische Modelle vor besondere Herausforderungen, die ihn von anderen Vorhersagedomänen unterscheiden. Das Verständnis dieser Herausforderungen hilft, realistische Erwartungen an die Genauigkeit von Prognosen zu entwickeln.
Die niedrige Torzahl pro Spiel ist das fundamentalste Problem. Im Durchschnitt fallen in einem Fußballspiel etwa 2,7 Tore. Das bedeutet, dass einzelne Spiele oft durch wenige Schlüsselmomente entschieden werden, und der Zufall eine große Rolle spielt. Im Basketball, wo hunderte von Punkten fallen, gleichen sich Zufallsschwankungen innerhalb eines Spiels aus. Im Fußball können sie das Ergebnis bestimmen.
Die Seltenheit extremer Ergebnisse erschwert die Modellierung der Ränder der Verteilung. Ein 7:0-Sieg kommt so selten vor, dass die Daten kaum ausreichen, um seine Wahrscheinlichkeit zuverlässig zu schätzen. Statistische Modelle tendieren dazu, solche extremen Ergebnisse entweder zu über- oder zu unterschätzen, je nach ihren Annahmen. Für die meisten praktischen Zwecke ist das irrelevant, aber für bestimmte Wettmärkte, die auf extreme Ergebnisse abzielen, kann es wichtig sein.
Die Instationarität der Daten ist ein weiteres Problem. Die Stärke von Mannschaften verändert sich im Laufe der Zeit durch Transfers, Verletzungen, Trainerwechsel und andere Faktoren. Historische Daten sind daher nur begrenzt aussagekräftig für zukünftige Spiele. Ein Modell, das ausschließlich auf Daten von vor fünf Jahren trainiert wurde, wird die aktuelle Situation nur unvollständig erfassen. Die Balance zwischen der Nutzung möglichst vieler Daten und der Relevanz dieser Daten ist eine ständige Herausforderung.
Vom statistischen Modell zur praktischen Nutzung
Die Übersetzung statistischer Erkenntnisse in praktisch nutzbare Vorhersagen erfordert einige zusätzliche Überlegungen, die über die reine Modellierung hinausgehen. Ein Modell kann noch so präzise und methodisch einwandfrei sein, wenn seine Ausgaben nicht richtig interpretiert und angewendet werden, bringt es keinen praktischen Nutzen und kann sogar zu Fehlentscheidungen führen.
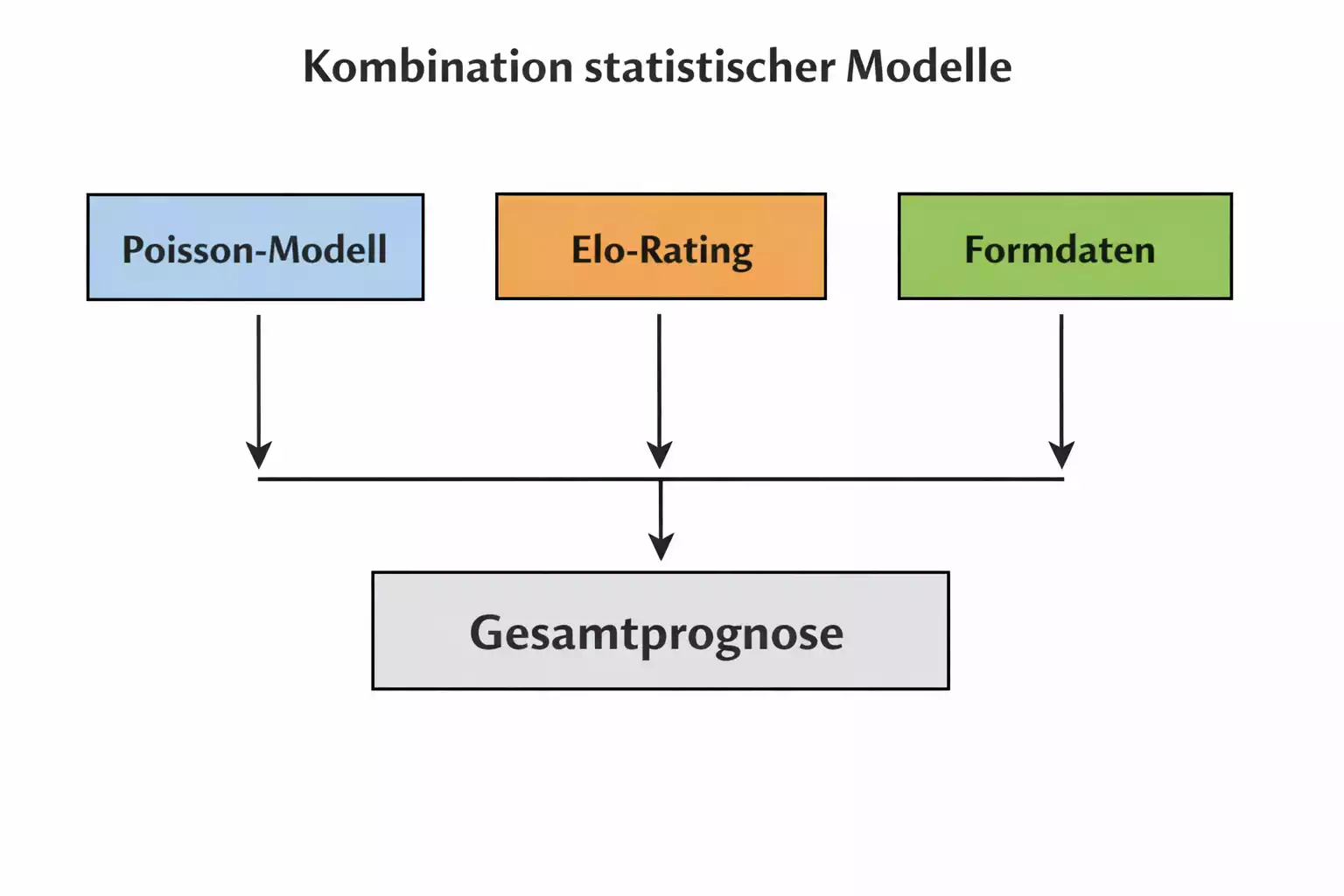
Die systematische Kombination mehrerer verschiedener Modelle führt oft zu besseren und robusteren Ergebnissen als die ausschließliche Nutzung eines einzelnen Modells. Verschiedene Modelle haben verschiedene Stärken und Schwächen, und ihre Vorhersagen können sich gegenseitig ergänzen und korrigieren. Ein Poisson-Modell könnte beispielsweise besonders gut darin sein, Torverhältnisse und Over-Under-Märkte vorherzusagen, während ein Elo-System besser die langfristige, fundamentale Spielstärke erfasst und weniger anfällig für kurzfristige Schwankungen ist. Die intelligente Kombination beider Ansätze, etwa durch gewichtete Mittelung oder Ensemble-Methoden, kann deutlich robustere Prognosen liefern als jeder einzelne Ansatz für sich allein.
Die sorgfältige Berücksichtigung von Kontextfaktoren, die nicht explizit in den Daten enthalten sind, kann die Vorhersagen weiter verbessern und verfeinern. Statistik erfasst naturgemäß nur das, was systematisch gemessen und aufgezeichnet wurde, aber nicht alles Relevante wird gemessen oder lässt sich messen. Die Motivation einer Mannschaft in einem bestimmten Spiel, die Bedeutung einer Partie für den Saisonverlauf, die Qualität und Tendenz des Schiedsrichters, die konkreten Wetterbedingungen am Spieltag sind Faktoren, die erheblichen Einfluss auf das Ergebnis haben können und die in vielen rein statistischen Modellen nicht explizit berücksichtigt werden. Die Integration solcher qualitativer Kontextfaktoren erfordert menschliches Urteilsvermögen, Erfahrung und Domänenwissen und kann die rein datengetriebenen Vorhersagen sinnvoll ergänzen.
Die fundamentale Akzeptanz von Unsicherheit ist vielleicht die wichtigste Lektion für die praktische Nutzung statistischer Vorhersagen im Fußball. Kein Modell, wie ausgeklügelt es auch sein mag, kann die Zukunft perfekt vorhersagen, und selbst die besten und sorgfältigsten Modelle werden regelmäßig danebenliegen. Das ist kein Versagen der Statistik oder der KI, sondern eine unvermeidliche Konsequenz der inhärenten Unvorhersehbarkeit des Fußballs als Sport mit niedriger Torzahl und hoher Varianz. Wer mit statistischen Vorhersagen arbeitet, muss diese fundamentale Unsicherheit akzeptieren und in alle seine Entscheidungen systematisch einbeziehen.
Die statistischen Methoden, die KI-Fußballvorhersagen zugrunde liegen, sind keine Hexerei oder Black-Box-Magie, sondern angewandte Mathematik mit einer langen und ehrwürdigen Geschichte. Poisson-Verteilungen, Elo-Ratings und bayesianische Methoden sind Werkzeuge, die von Menschen entwickelt wurden, um systematisch mit Unsicherheit umzugehen und aus unvollständigen Daten zu lernen. Das Verständnis dieser Werkzeuge entmystifiziert die KI und ermöglicht eine kritische, informierte Bewertung ihrer Vorhersagen. Am Ende steht die nüchterne Erkenntnis, dass Statistik den Zufall nicht besiegen kann, sondern nur hilft, ihn besser zu verstehen und mit ihm umzugehen.